
Why Subprime Mortgage Losses Mattered in the 2008 Financial Crisis

“In 2007, many analysts dismissed the significance of subprime mortgage losses, which they compared to a bad day in the stock market. In a report that November, Hatzius called the analogy flawed. Citing research by the economists Tobias Adrian and Hyun Song Shin, he noted that stocks were mostly owned by ‘long-only’ investors such as pension funds who ‘passively accept a hit to their net worth.’
By contrast, mortgages are owned by leveraged institutions such as banks, investment dealers, hedge funds, Fannie Mae and Freddie Mac. For every dollar of losses, these investors would have to shrink their balance sheets to preserve their capital ratios. This was a key reason Hatzius projected weaker growth and a higher risk of recession in 2008 than the consensus.”
From Happiness Data to Economic Conclusions—Video of a Presentation at LSE by Ori Heffetz →
A talk about joint work with Dan Benjamin, Kristen Cooper and me.
Posts Useful for Teaching
On Learning
On Writing
Intermediate Macro
Happiness
Getting Free Of Self-Importance Is The Key To Happiness—Polly Young-Eisendrath
What Makes a Good Life? Lessons from the Longest Study on Happiness—Robert Waldinger
Measuring National Well-Being
Political Polarization and Wokeness
Economics Is Unemotional—And That's Why It Could Help Bridge America's Partisan Divide
Although the United States is Not Woke Enough, Its Universities are Now Too Woke
Ethics and Choice
Meeting the Enemy: A Feminist Comes to Terms with the Men's Rights Movement—Cassie Jaye
Raj Chetty on How Cross-Class Interactions When Young are a Key to Poor Kids Rising
What David Laibson and Andrei Shleifer are Teaching for Behavioral Economics—Jeffrey Ohl
How People Differ from One Another Psychologically: IQ and the Big 5—Jordan Peterson
Although the United States is Not Woke Enough, Its Universities are Now Too Woke
Jarvis Givens on Education and Learning as a Way to Fight Back against Racism
Justin Wolfers: More Women Than Men Are Going to College. That May Change the Economy.
Jordan Peterson
Jordan Peterson Shows How to Engage Your Audience by Respecting Them
Jordan B. Peterson on the True Purpose of a University Education
How People Differ from One Another Psychologically: IQ and the Big 5—Jordan Peterson
Jordan Peterson on Ideological Possession: 'You don't Have Ideas; Ideas Have You'
Jordan Peterson on Jung, Human Potential and the Imitation of Christ
Jordan Peterson on How there *is* Reality *and* Values are a Part of Science
Jordan Peterson on the Downside and Upside of the Patriarchy
Jordan Peterson on Ideological Possession: 'You don't have Ideas; Ideas have You'
Sometimes the Devil You Don't Know is Better than the Devil You Do
Statistics
The Supposed Health Benefits of Moderate Drinking are a Crock
'Vibration of Effects' as a Tool for Seeing How Sensitive an Associational Study is to Tweaks
Evidence that Air Pollution Messes Up Babies' Gut Microbiome—with Many Downstream Consequences
A Linear Model for the Effects of Diet and Exercise on Health is a Big Advance over Popular Thinking
Some Low Hanging Fruit for Government Policy: Paying Benefits and Wages to Low-Income Folks Weekly
Cognitive Behavioral Therapy for Insomnia Can Prevent Major Depression
Noise Pollution is More than a Nuisance. It’s a Health Risk. —Stephanie Dutchen
Suggestive Evidence that Vitamin D Supplements Lower Risk of Autoimmune Disease
An Example of Ideology Leading to Bad Statistics and Social Injustice
Monetary Policy
Brad DeLong Confirms that Not Having Negative Interest Rate Policy in the Monetary Policy Toolkit
How a Toolkit Lacking a Full Strength Negative Interest Rate Option Led to the Current Inflationary Surge Makes People Afraid of Vigorous Rate Hikes to Control Inflation
Nominal Illusion: Are People Understanding Real Versus Nominal Interest Rates?
Analyzing the Great Depression Using Supply and Demand for the Monetary Base
Ruchir Agarwal and Miles Kimball on Negative Interest Rates and Inflation—IMF Podcasts
Business Cycle Theory
Finance
Matthew Yglesias: If the Platinum Coin is Too Weird, Meet High-Yield Bonds
The 'Portfolio Rebalancing in General Equilibrium' Interview
Political Economy
Basic Facts
Economic Growth
Housing Policy and Technology
Political Victories for the Supply-Side in Housing: The Long March of the YIMBYs—Noah Smith
Zachary Sonntag: How the Need for Affordable Middle Housing Runs Up Against Zoning Laws
How Do You Make Middle Housing More Appealing? Make It Look Like a Single-Family Home—Zakary Sonntag
Education Policy
Immigration
Futurism
Supply-Side Liberalism

Zombie Firms, Risk-Taking and Interest Rates
Link to the YouTube video shown above. h/t Torsten Slok
The video above is a nice discussion of zombie firms, with a bit of discussion of “cash” vs. risky assets toward the end. I was reminded of two passages I wrote in my post “Contra John Taylor,” in 2013:
**********
Low rates and zombie loans.
The low rates also make it possible for banks to roll over rather than write off bad loans, locking up unproductive assets.
This is one of John’s best and most interesting points. It is a quirk of traditional loan contracts that the repayment rates expected by lenders are sometimes slower when nominal interest rates are low. This is a place where the free market should do its magic, with lenders making sure that the rates at which they are supposed to be repaid are adequate to help them identify badly-performing loans early on. The free market will get better at this the more experience businesses have with low nominal interest rate environments.
***********
Low interest rates as fuel for speculation. Here, he says
The Fed’s current zero interest-rate policy also creates incentives for otherwise risk-averse investors—retirees, pension funds—to take on questionable investments as they search for higher yields in an attempt to bolster their minuscule interest income.
I can’t make sense of this statement without interpreting it as a behavioral economics statement about some combination of investor ignorance and irrationality and fraudulent schemes that prey on that ignorance and irrationality. The often-repeated claim that low interest rates lead to speculation cries out for formal modeling. I don’t see how such a model can work without some combination of investor ignorance and irrationality and fraudulent schemes preying on that ignorance and irrationality. (That is, I don’t see how the claim could hold in a model with rational agents and no fraud.) Whatever combination of investor ignorance and irrationality and fraudulent schemes preying on that ignorance an irrationality a successful model uses are likely to have much more powerful implications for financial regulation than for monetary policy. It is cherry-picking to point to implications of a not-fully-specified model for monetary policy and ignore the implications of that not-fully-specified model for financial regulation.
Toward a National Index of Well-Being—Kristen Cooper →
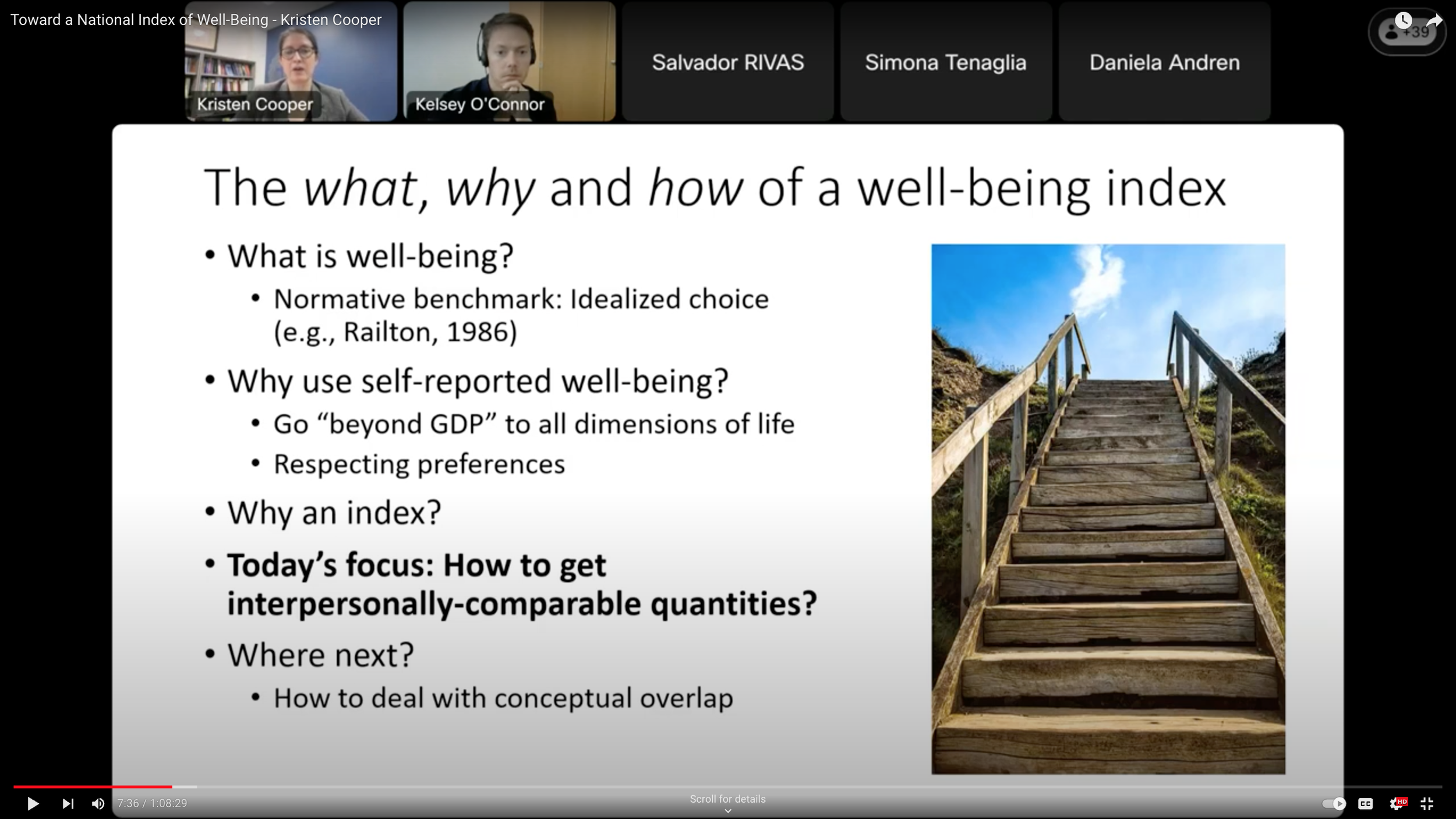
Link to the video shown above on YouTube
In this video, my coauthor Kristen Cooper gives a run down of most of the work I have been involved in using self-reported well-being data. Both Kristen and I answer questions at the end.